RESILIENCE COMPUTING
Spectrum of solutions for continuity of operations
EXCELLENCE IN COMPUTING
C3S started as a hardware resilience solution provider to mission-critical customers in Singapore and the region. Customers included government, regional stock exchanges, national utility providers, high-value manufacturers, just to name a few.
We offer a spectrum of fault tolerant solutions to provide our customers with continuity of their operations upon failure of a component in their information and communication technology (ICT) system that their operations are critically dependent on.
We take a lifecycle approach to resilience.
Specification, Procurement and Implementation of a Resilience Computing Solution using our Resilience Framework
Resilience Preventive Maintenance to systematically check the proper operation of a mission-critical system.

RESILIENCE COMPUTING SOLUTIONS
We offer three fault tolerant solutions to meet a variety of resilience specifications and budgets. The chart below summarises the resilience behaviours of the three fault tolerant solutions that we offer:
-
Hardware Fault Tolerance
-
Software Fault Tolerance
-
High Availability.
ANALYSED USING OUR OPERATIONS RESILIENCE ANALYSIS FRAMEWORK
We use our Operations Resilience Analysis Framework to describe, assess and test the resilient characteristics of the three solutions. The resilient characteristics are measured and compared in the dimensions of:
Recovery Latency – the length of downtime when the system is not performing normally
Data Loss Vulnerability – the risk of data loss and data corruption during failover
Our Resilience Notation is used to represent and then analyse and communicate the resilience design and recovery behaviour during a failure of each resilient computing system. The Notation is used as a basis for walking through a time series simulation of the resilience design in great detail.
HARDWARE FAULT TOLERANCE SOLUTION
RESILIENCE DESIGN
In the hardware fault tolerance solution:
Primary and secondary both process same transaction which is kept in sync by a lockstep mechanism
Sensors detect failure in: memory, hard disk, CPU, network card, power supply unit
Failover mechanism promotes secondary hardware
Secondary hardware continue processing seamlessly as nodes are kept in sync by lockstep mechanism
COMPARISON
Hardware Fault Tolerance compared with Software Fault Tolerance and High Availability solutions:
Recovery latency is zero
Data Loss Vulnerability is zero
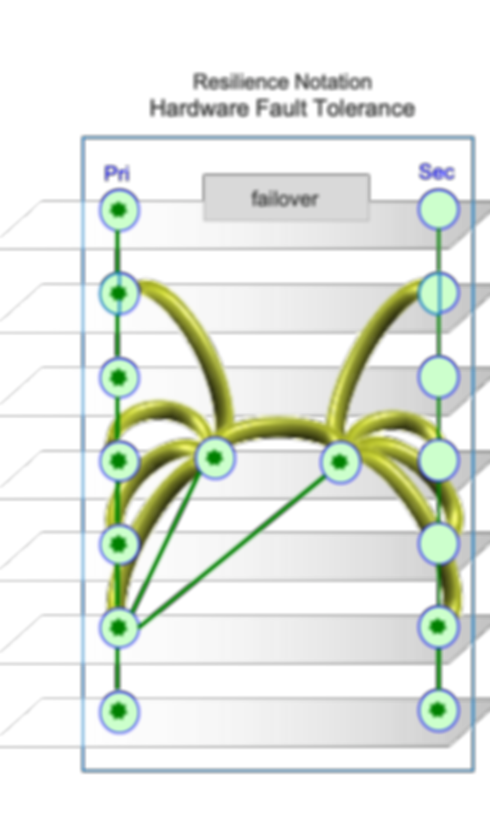
HARDWARE FAULT TOLERANCE
Resilience Notation
Resilience Notation explains failover process:
During normal operation: Application running lockstep in both Primary and Secondary
Failover Process: Primary stops running due to a fault. Secondary running in Lock Step is not affected.
Secondary continues operating: Secondary running in lockstep is not affected by failure of Primary.
Result of Hardware Fault Tolerance Failover Process:
Application is processed in Lock Step by both primary & secondary
In the event of failure, output of the other system is used, resulting in:
no data loss
no recovery latency.
SOFTWARE FAULT TOLERANCE SOLUTION
RESILIENCE DESIGN
Software Fault Tolerance design uses a state-pointing process where data in storage and memory are being replicated and synchronized from the primary to the secondary. To do this no input and output can leave the primary server until any modified memory data has been mirrored to the secondary server.
When failures occur the secondary server will continue operation from the last state-point.
COMPARISON
Software Fault Tolerance compared with Hardware Fault Tolerance and High Availability solutions:
Recovery latency is low
Data Loss Vulnerability is low.

SOFTWARE FAULT TOLERANCE
Resilience Notation
Resilience Notation explains failover process:
During normal operation: The application is running in the Primary. The Application, Data and Operating System status copied to Secondary.
Failover Process: Primary stops running due to a fault
Failover to Secondary. Secondary recover from latest status stored. Secondary resumes operation.
Result of Software fault Tolerance Failover Process:
Secondary recovers with data in memory and disk
Data in memory & not replicated to secondary is lost
Application is not available while:
Time detect failure
Failover to secondary
Recovery of application with data memory of secondary.
HIGH AVAILABILITY SOLUTION
RESILIENCE DESIGN
Resilience Design:
High Availability design uses a check-pointing process where data in storage in primary server is replicated to storage in the secondary server but not in-memory data.
If a failure occurs, the data is rolled back to its last known state.
If failure is on the primary server, a restart is needed and the restart time is specific to the application.
COMPARISON
High Availability compared to Hardware Fault Tolerance and Software Fault Tolerance:
Recovery latency is high
Data Loss Vulnerability is high.
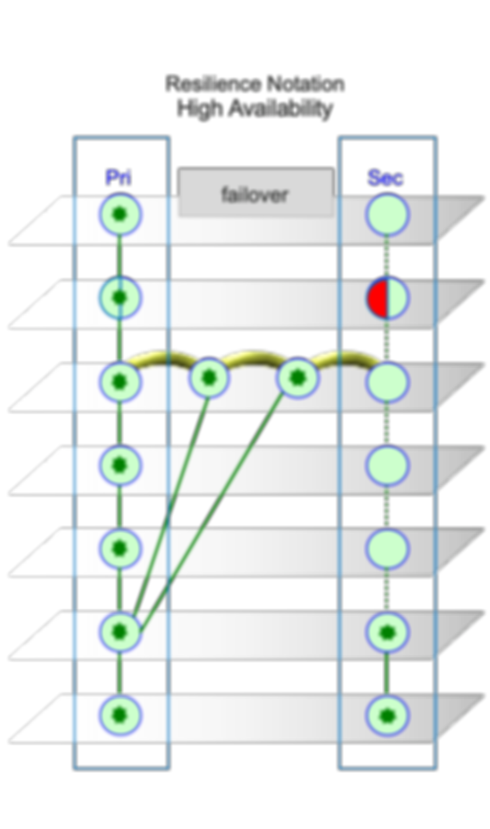
HIGH AVAILABILITY SOLUTION
Resilience Notation
Resilience Notation explains failover process:
During normal operations: The application running in the Primary. Data in storage of primary server copied to storage of secondary servier.
Failover Process: Primary stops running due to fault.
Failover to Secondary: Application is restarted in secondary server from latest data stored in storage of secondary server. Secondary resumes operation.
Software fault Tolerance Failover Process
Secondary recovers with data in disk
Data in memory & not replicated to secondary is lost
Data in primary storage & not replicated to secondary storage is lost
Application is down while:
Time detect failure
Failover to secondary
Restart application with data memory of secondary.
RESILIENCE PREVENTIVE MAINTENANCE
The objective of the Resilience Preventive Maintenance is to systematically check the proper operation of a mission-critical system especially the proper operation of the failover mechanism. Proper operation of the failover mechanism is essential to the resilience of the mission-critical system as the continuity of operation of the mission-critical system depends on the successful failover from the primary to the secondary should a fault occur in the primary.
There are two types of maintenance commonly practised in a resilience system, Preventive Maintenance and Corrective Maintenance. Preventive Maintenance is the service before the fault by ensuring the system is maintained to its specifications. While Corrective Maintenance is the action after a fault to restore the system back to its specifications. For the purpose of resilience, we focus on Preventive Maintenance as it has far more impact on the resilience of the system compared to Corrective Maintenance which merely restores a failed operation.
The purpose of maintenance is about restoring the specifications. We are looking for specifications that can deteriorate over the use of the system, perhaps less static and can dynamically change according to the usage of the system. For example, the specifications of a tyre may be the size and the maximum air pressure it can take, but the operating specifications of the tyre are about the optimal air pressure to maintain and the depth of the rubber groove for water displacement and traction.
